Designing the future of fraud prevention
Designing a vertical-agnostic system
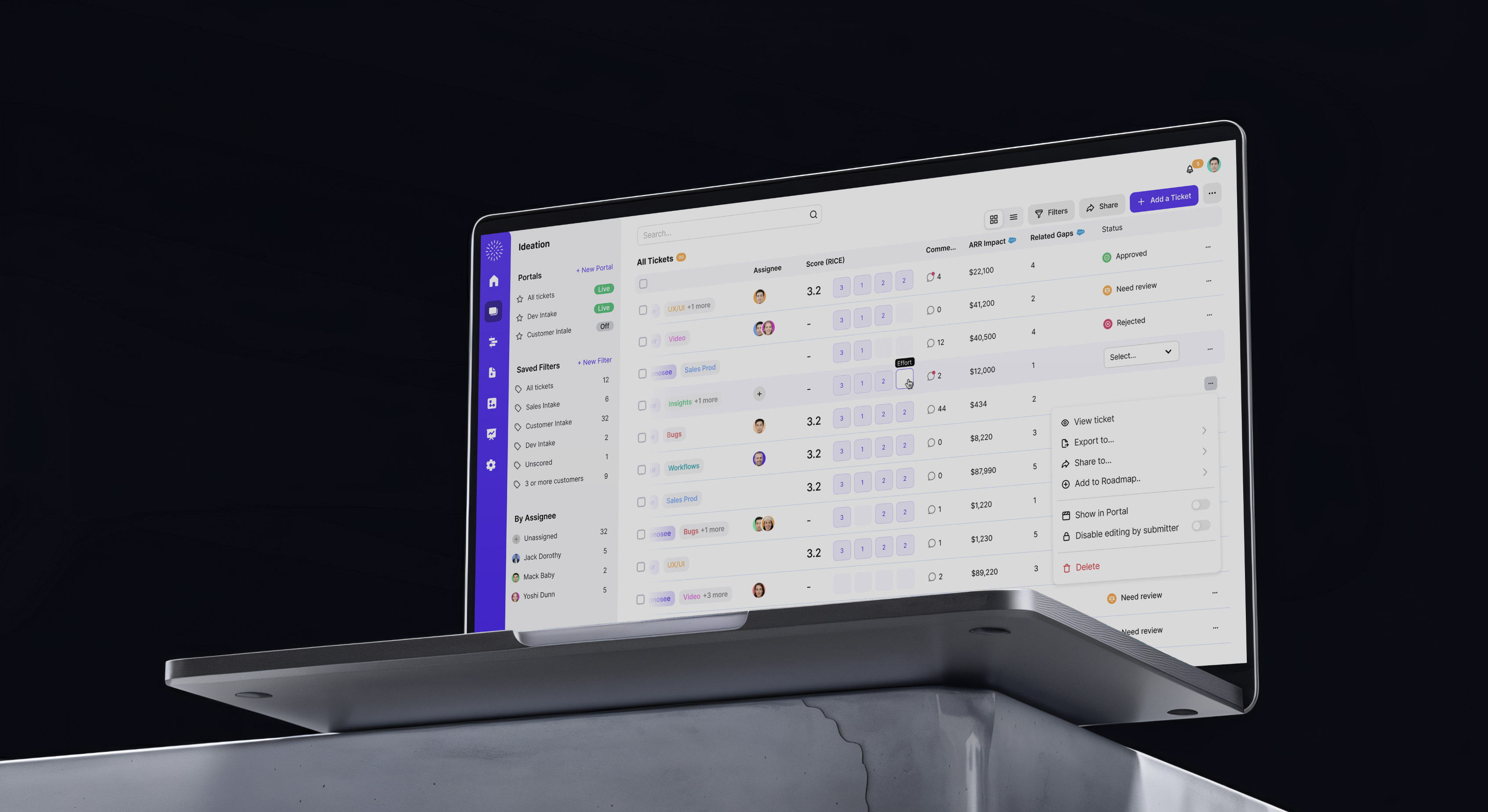
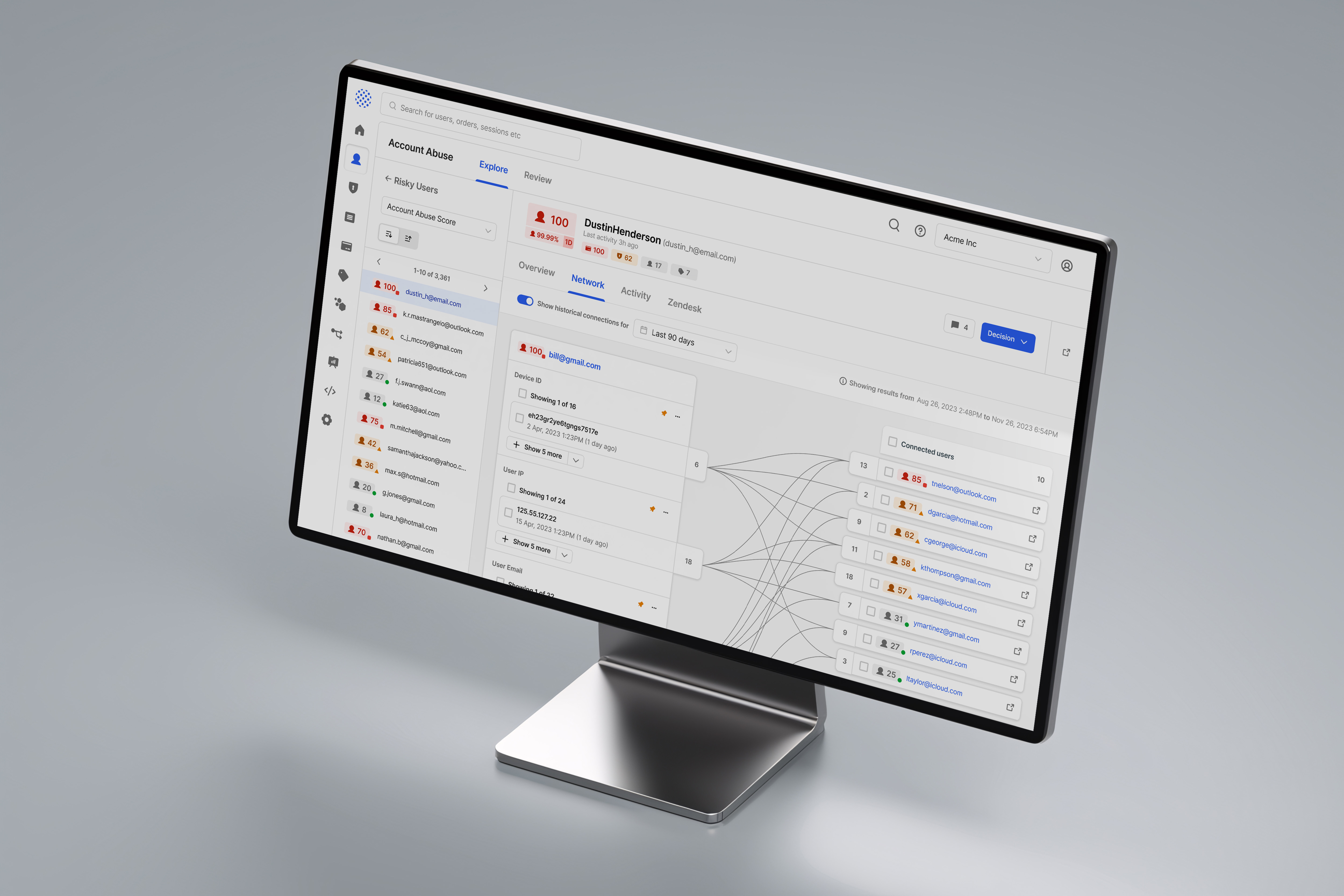
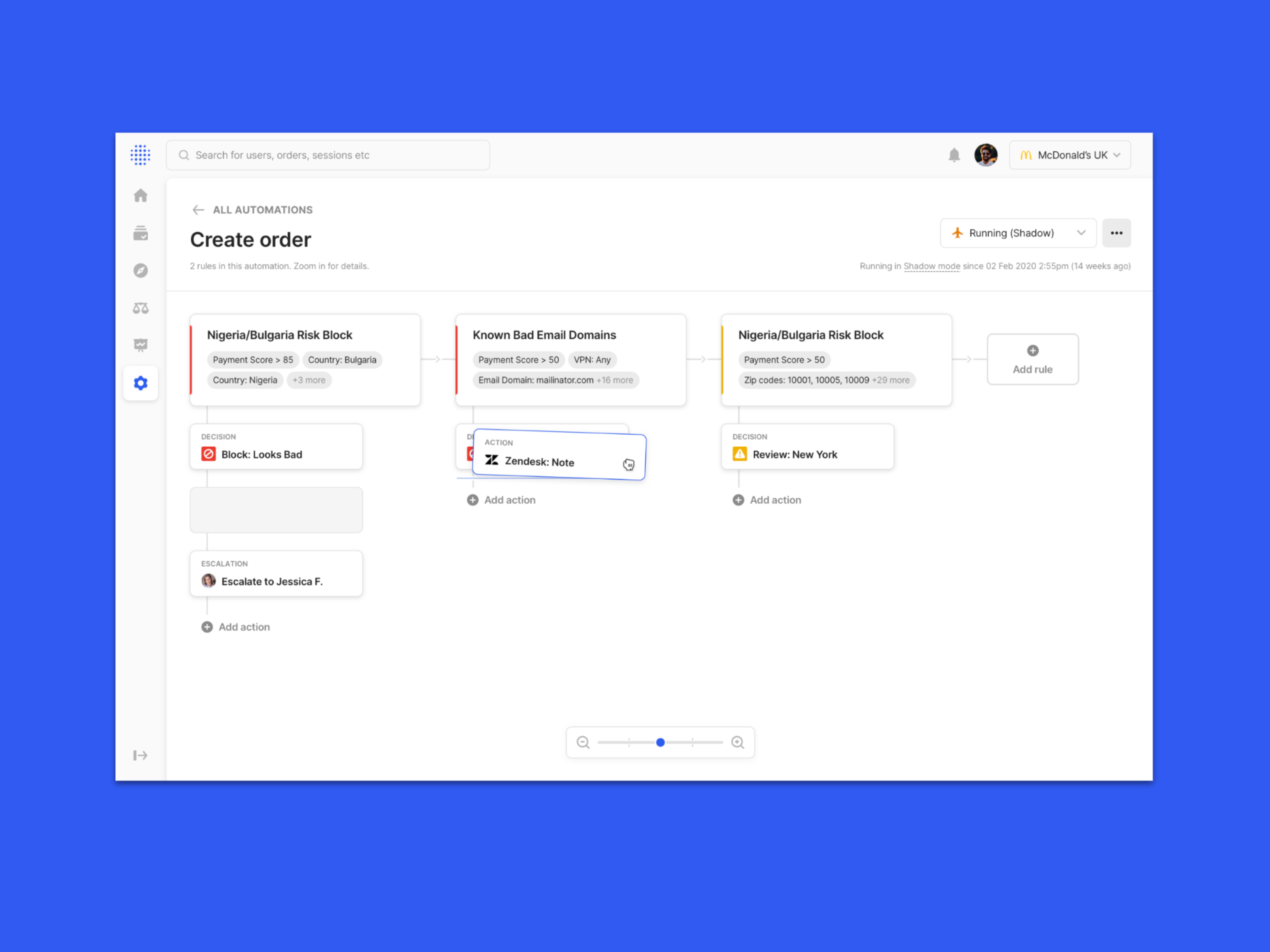
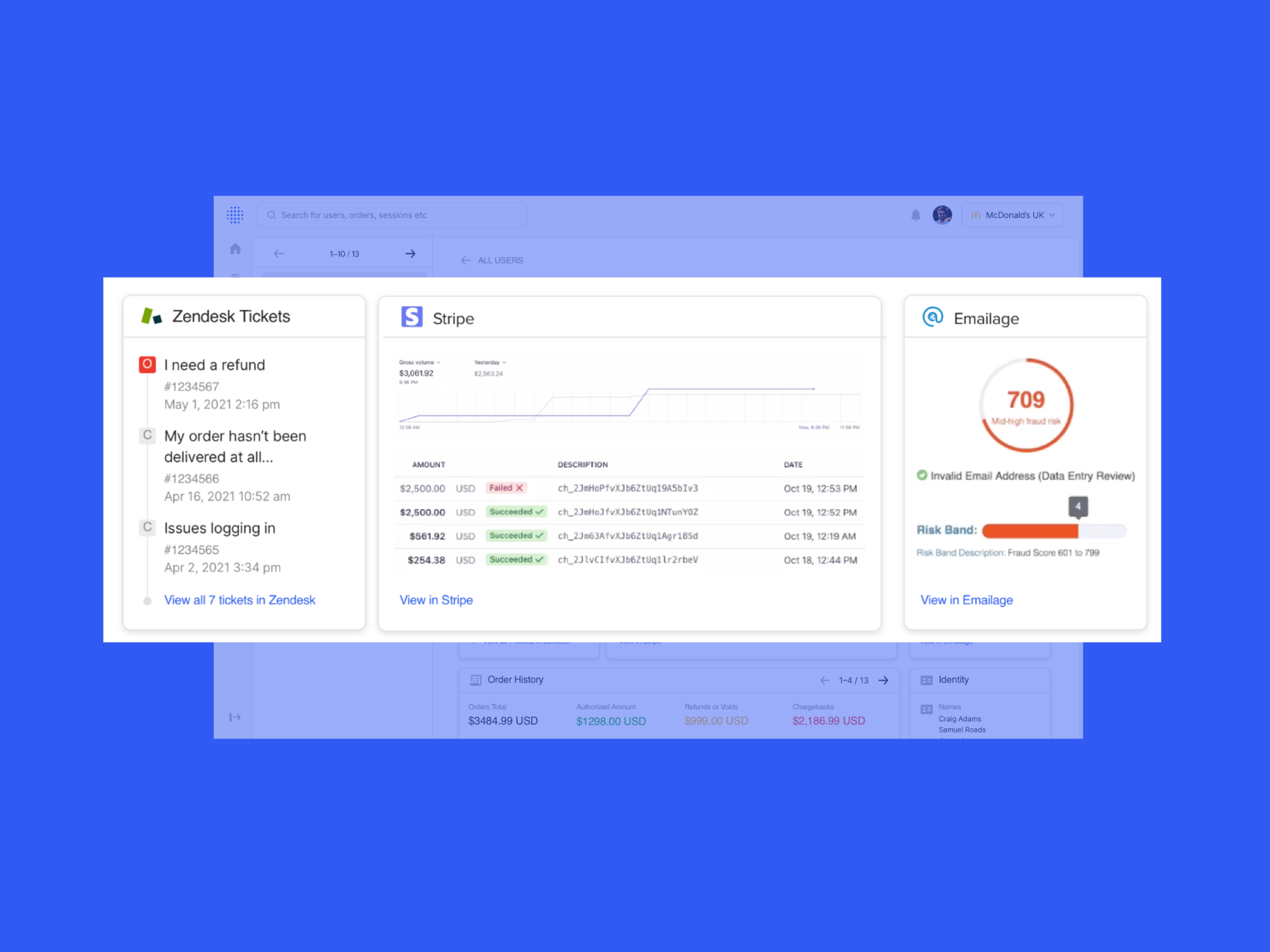
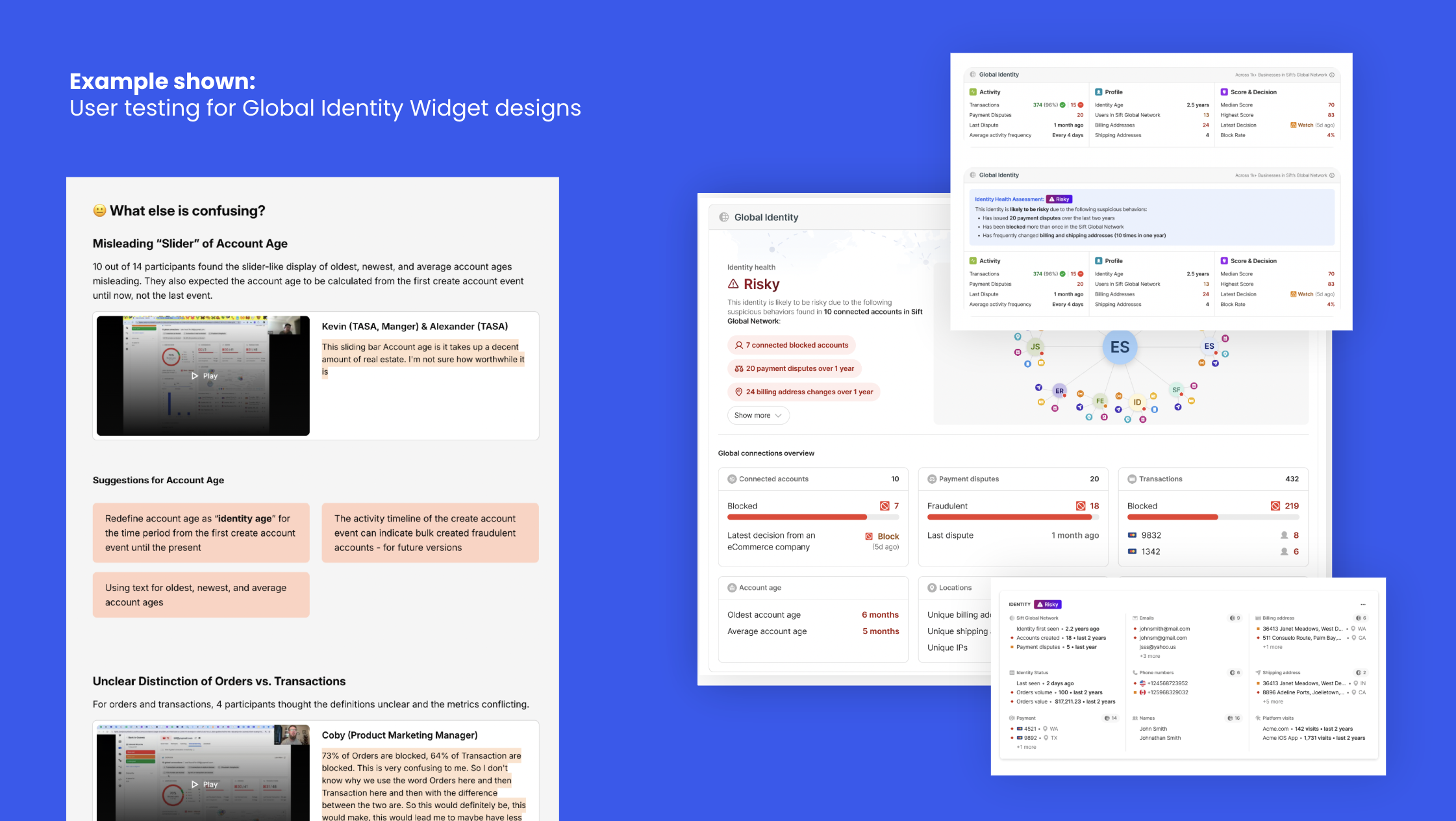
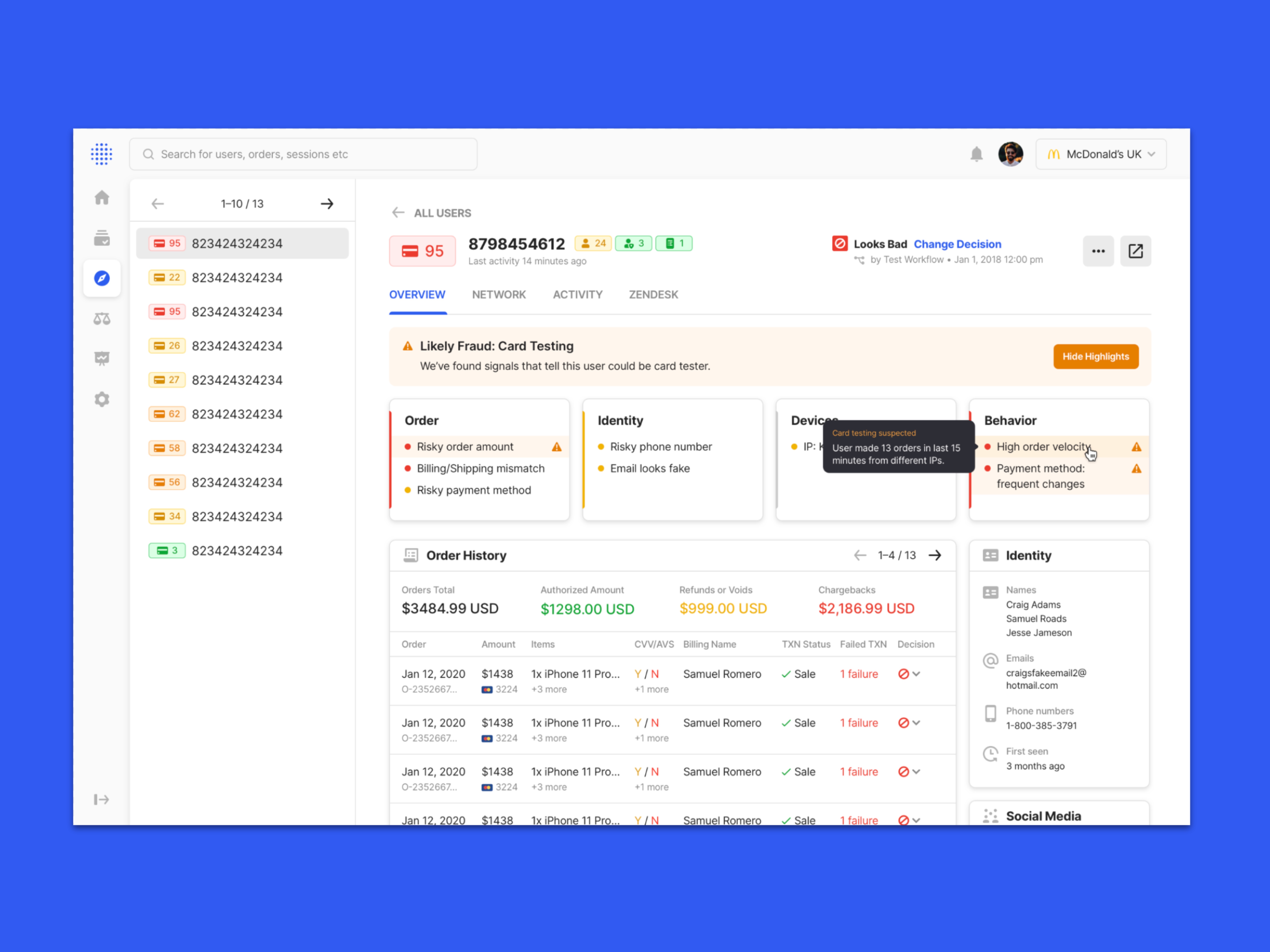
**case studies available on demand** Sift enables fraud teams to investigate and prevent fraud using thousands of data points about every transaction, login, order, or other event. Those data points allow Sift to produce a score that signals the likelihood of fraud per event. At first, we were mainly targeted at e-commerce, brick & mortar, and startup companies, but leadership wanted the console to be able to easily expand to new verticals, such as Airlines, Fintech, and iGaming. Through extensive research, we also learned how fraud agents use our platform alongside other tools and systems, which meant the vertical expansion had to account for a deeper approach.


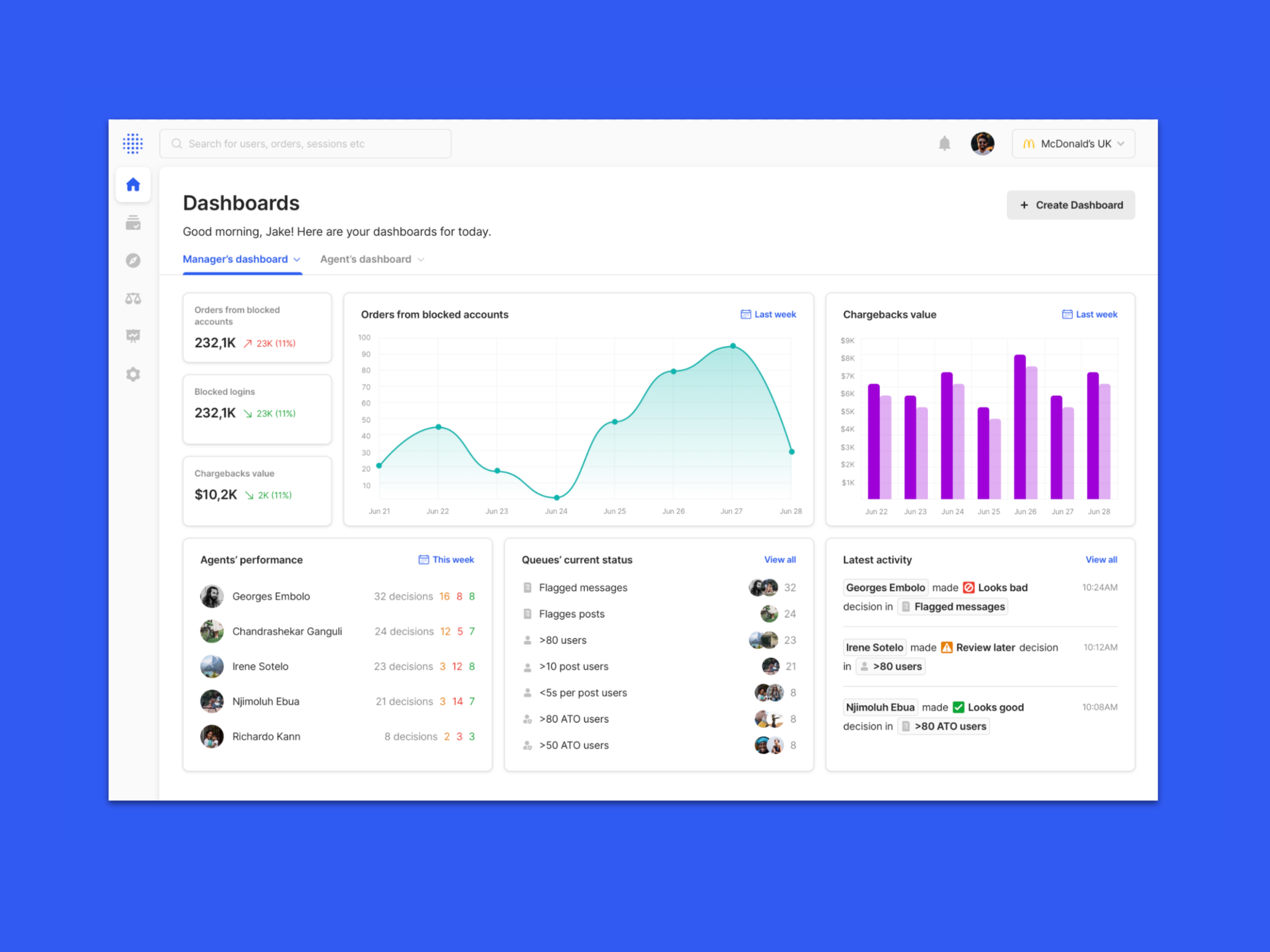
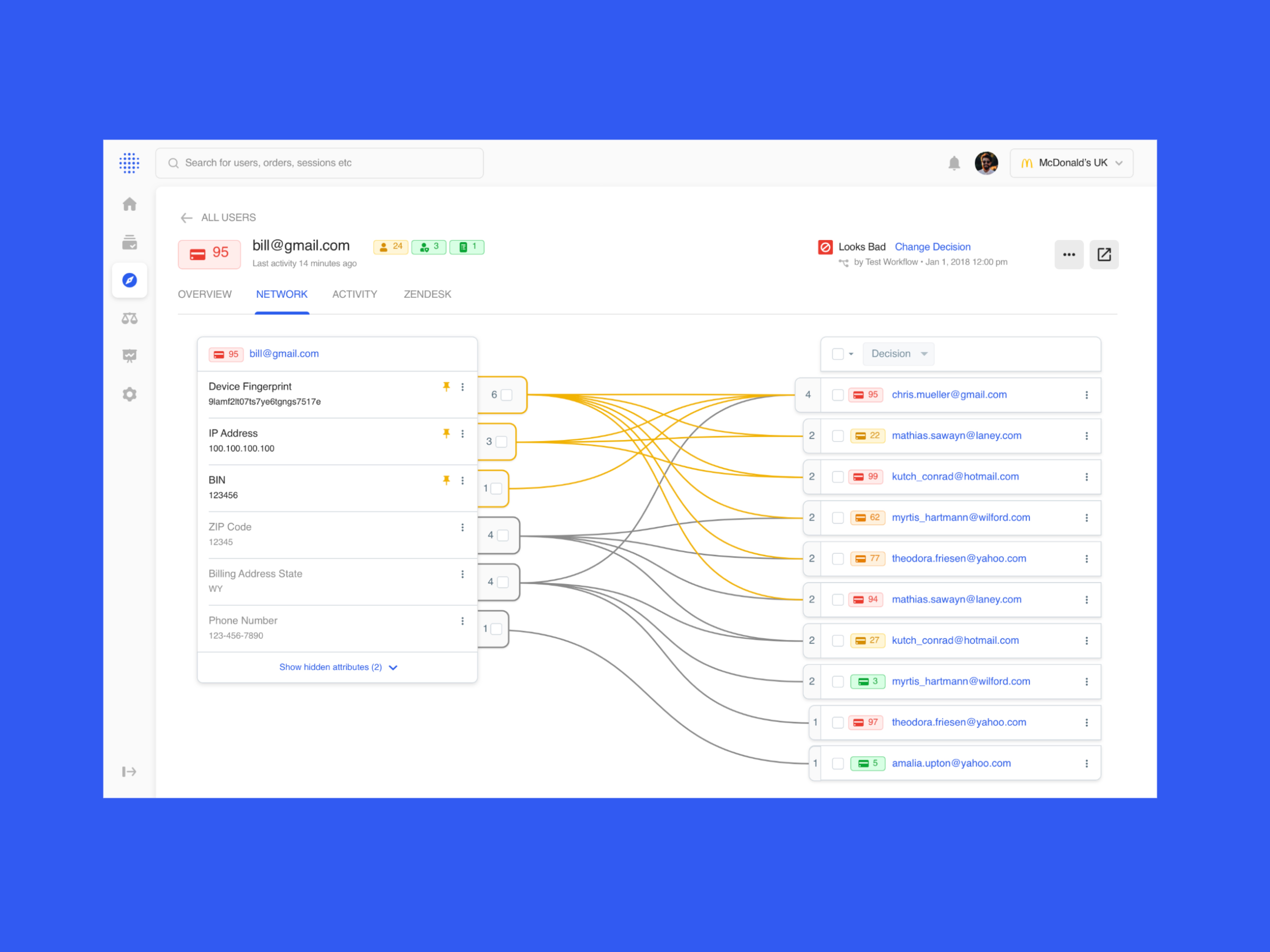


Fraud is dynamic, and so is our Console
To enable this, we created an WCAG-accessible framework for building widgets, tools, and other elements for any fraud vertical, so that a Sift dev team can easily build what they need with consistency, without the need to create new UI or elements. We also produced new investigation mechanisms, like signal severity system, smart drill downs and AI-helpers for context and actionable help.